ale_xb
-
Постов
56 -
Зарегистрирован
-
Посещение
Достижения ale_xb
Продвинутый пользователь (3/6)
1
Репутация
-
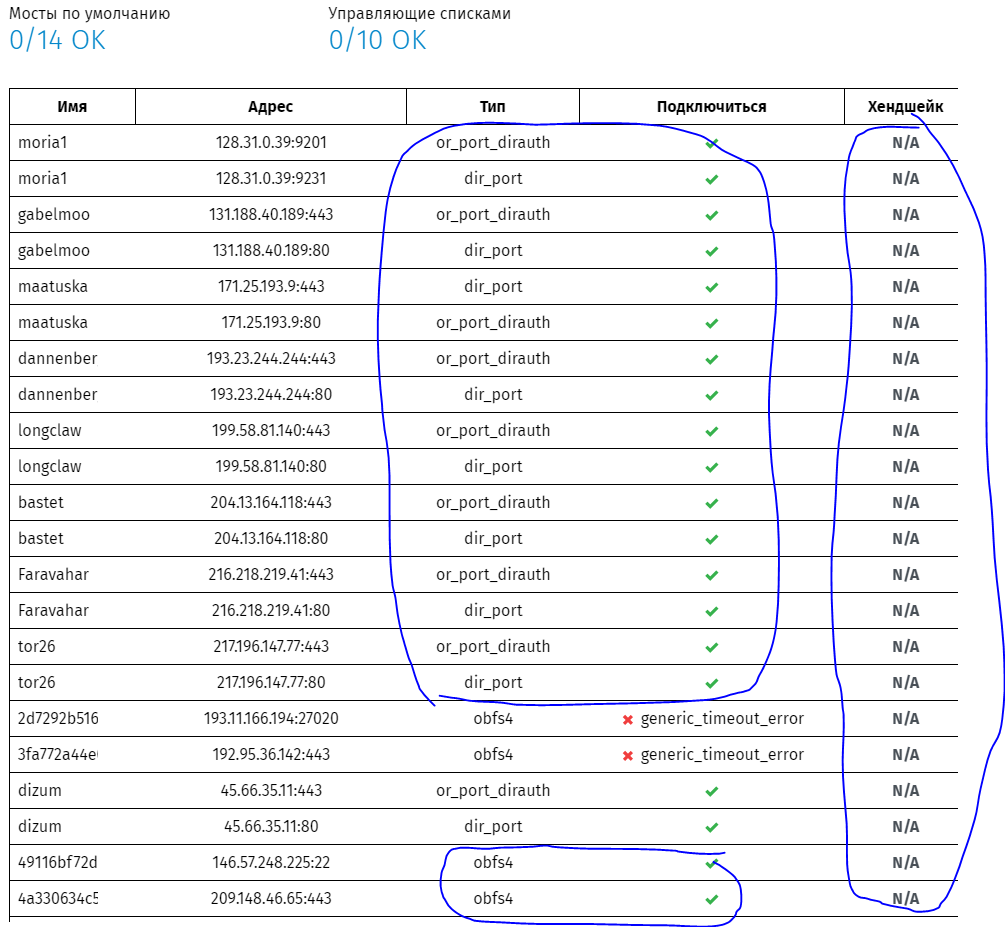
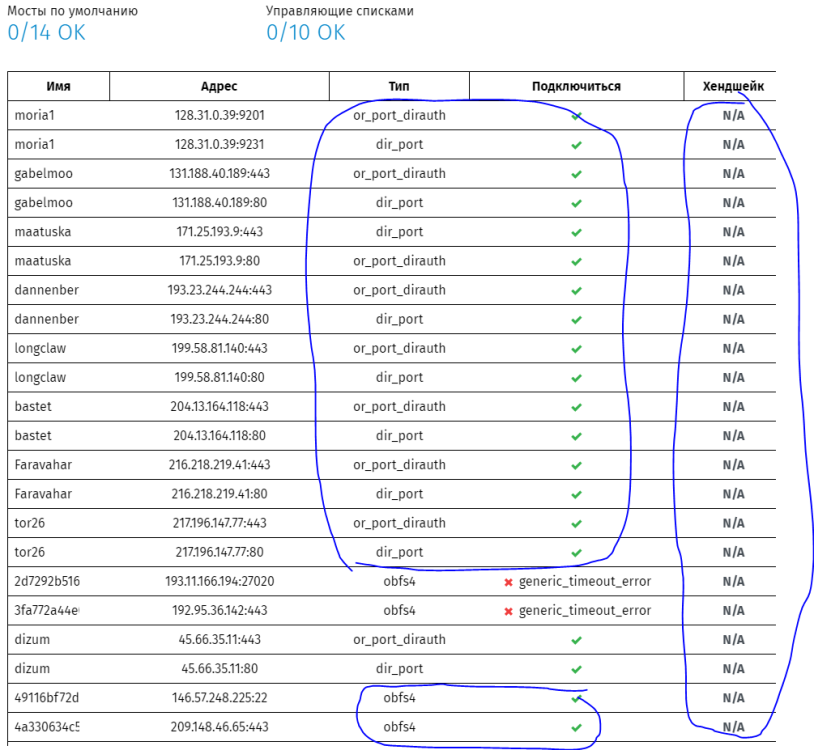
Спасибо, оказался сам себе злобный Буратино. Зачем-то в настройках прозрачного прокси в torrc для TransPort указал 127.0.0.1/::1. Сменил на 0.0.0.0/:: и все заработало. Наверное, правильнее вместо этого указать 192.168.1.0/24, но не уверен, какой из адресов в этом случае следует указывать для Ipv6 - linklocal вида fe........? Итог: в tor теперь перенаправляется tcp (udp не проверял) трафик по IPv4/IPv6 (проверено). Работают obfs4, webtunnel, snowflake (все три варианта проверены). Старая черная ultra еще поработает!
-
продолжаю пока сам с собой: Установил из Entware lyrebird, указал к нему путь в torrc, получил возможность использовать мосты obfs4, webtunnel, snowflake. Нашел/запросил 100% рабочие мосты, проверил их в Tor Browser на Windows клиенте, затем вписал их в torrc на роутере. На роутере tor успешно поднимается (Bootstrapped 100%), в логах видно, что к мостам есть успешное подключение, но при попытке открыть на клиенте в браузере (не в Tor Browser, а в обычном) любой ресурс, предварительно внесенный в список для доступа через tor, получаю сообщение ERR_CONNECTION_REFUSED. При этом 1) имя ресурса успешно разрешается в IPv4 и (при его наличии) в IPv6; 2) Оба адреса успешно добавляются в соответствующие ipset; 3) Правила в цепочке PREROUTING таблицы nat с редиректом на порт прозрачного прокси tor для обоих вариантов адресов имеются и 4) видно, что счетчик пакетов для правил увеличивается в момент обращения на ресурс. В Tor Browser ресурс открывается успешно с этими же мостами. В чем могут быть отличия в работе tor и мостов на роутере и в Tor Browser на Windows клиенте? Что следует проверить, поправить? Дополнительно, сделал тест: очистил все ipset, остановил tor на роутере и проверил доступность сети tor с помощью OONI Probe. Результат - подключения проходят, хэндшейк - нет, но гугл говорит, что это может быть нормально. Как же Tor Browser умудряется работать и как добиться того же на роутере? Могут ли здесь помочь манипуляции с mtu, mss ? Есть предположение, что я что-то напутал в а) конфиге dnsmasq, б) правилах для DNS и редиректа на прозрачный tor прокси. У меня установлен и настроен Dnsmasq + в веб интерфейсе Кинетик-а DoT/DoH резолверы + у tor работает свой DNS. Транзитные запросы запрещены.
-
у меня целая пачка вопросов по мостам в Tor, буду признателен за ответы: Кто-то настраивал webtunnel+Tor на Keenetic? Можете подсказать, что для этого необходимо? Нужен более свежий транспорт lirebird Достаточно ли для этого установить из opkg/entware webtunnel-client lirebird? да webtunnel-server при этом не требуется? Как это правильно прописать в torrc? аналогично obfs4 Почему-то сообщество Tor выдает мосты для webtunnel только для ipv6. Это так и есть или я что-то неправильно запросил/посмотрел? Я правильно понимаю, что obfs4 и webtunnel - в текущей реализации взаимоисключающие вещи? Нет. Читал, что lyrebird умеет работать одновременно с различными транспортами, но этого (пока?) нет в opkg/entware. Есть.
-
Спасибо, понял. Звонки между трубками по внутренним номерам, вероятно, идут по каким-то протоколам DECT и SIP здесь снова ни при чем, верно?
-
а можно ли к Keenetic DECT подключиться каким-либо софтфоном или аппаратным терминалом по SIP без установки Астериск? Что-то я в netstat даже не вижу, чтобы кто слушал порт 5060.
-
у меня на Ultra II с некоторых пор Tor 0.4.8.16 + obfs4 отжирает почти все процессорные ресурсы, но ОЗУ хватает, остается свободно из 256Мб процентов 40. ОС 4.2.6. Web интерфейс и CLI по ssh практически перестают откликаться. Последним сдается родной shell Keenetic, но и он еле шевелится. Останавливаю tor (если удается что-то в Cli сделать), все приходит в норму. Что бы проверить/поправить прежде всего? Пробовал в torrc добавить параметр NumCPUs 2, но разницы не заметил.
-
Конечно (только не забудьте на имена своих интерфейсов, номера таблиц маршрутизации, маркировки сменить): #!/bin/sh [ "$1" == "hook" ] || exit 0 [ "$layer" == "link" ] || exit 0 [ "$id" == "Wireguard2" ] || exit 0 IF_NAME=nwg2 IF_GW4=$(ip -4 addr show "$IF_NAME" | grep -Po "(?<=inet ).*(?=/)") case ${layer}-${level} in link-disabled|link-pending) logger "====WG2 DOWN=====" ip -4 rule del fwmark 0xd1000 lookup 1001 priority 1778 2>/dev/null ip -4 route flush table 1001 ;; link-running) logger "====WG2 UP=====" ip -4 route add table 1001 default via "$IF_GW4" dev "$IF_NAME" 2>/dev/null ip -4 route show table main |grep -Ev ^default |while read ROUTE; do ip -4 route add table 1001 $ROUTE 2>/dev/null ip -4 rule add fwmark 0xd1000 lookup 1001 priority 1778 2>/dev/null ip -4 route flush cache ;; esac exit 0
-
Спасибо. Работает! Я на всякий случай добавил оба условия и потерю коннекта и "административный down": case ${layer}-${level} in link-disabled|link-pending) .... link-running) .....
-
Обновился (старенькая черная Ultra II, ветка delta) с версии 3.9.8 до версии 4.1.7 (4.01.C.7.0-1) и что-то сломалось. Настраивал выборочный роутинг с помощью ipset и dnsmaq-full по описанию из соседней (теперь удаленной/закрытой) на этом форуме ветке. Похоже, перестал отрабатывать хук-скрипт /opt/etc/ndm/ifstatechanged.d/10m-redirect4.sh из-за того, что статусы используемого мною vpn интерфейса теперь как-то иначе отображаются. Добавил в скрипт строку для их логирования logger ${id}-${change}-${connected}-${link}-${up} и вот, что получил в результате при ручном включении/выключении в веб-интерфейсе настроенного и рабочего Wireguard туннеля: Aug 8 21:26:02 keenetic ndm: Core::System::StartupConfig: configuration saved. Aug 8 21:26:02 keenetic ndm: Network::Interface::Base: "Wireguard2": "wireguard" changed "link" layer state "pending" to "running". Aug 8 21:26:02 keenetic root: Wireguard2-link-no-up-up Aug 8 21:26:02 keenetic root: Wireguard2-link-no-up-up Aug 8 21:26:24 keenetic ndm: Network::Interface::Base: "Wireguard2": "base" changed "conf" layer state "running" to "disabled". Aug 8 21:26:24 keenetic ndm: Network::Interface::Base: "Wireguard2": interface is down. Aug 8 21:26:24 keenetic ndm: Core::System::StartupConfig: saving (http/rci). Aug 8 21:26:24 keenetic root: Wireguard2-link-no-up-up Aug 8 21:26:24 keenetic kernel: wireguard: Wireguard2: peer "xxxxxxxxxxxxxxxxxxx" (15) (xxx.xxx.xxx.xxx:xxxx) destroyed Aug 8 21:26:24 keenetic root: Wireguard2-link-no-up-up Aug 8 21:26:28 keenetic ndm: Core::System::StartupConfig: configuration saved. Не понятны 2 вещи: 1. При поднятии/отключении интерфейса Wireguard (state "pending" to "running" и state "running" to "disabled") получаю почему-то по ДВЕ записи в лог, а не одну. 2. При поднятии и отключении интерфейса обе записи одинаковые (Wireguard2-link-no-up-up), поэтому скрипт не работает, дополнительная таблица 1001 для роутинга не создается. Что мне следует проверить/исправить?
-
Судя по тому, что уже тестируется 4.0 alfa 5 и в списке есть, например, интересующая меня Ultra II надежда есть!
-
Я все же не понимаю, как конфиг из web-интерфейса (для ipv4 только) будет соседствовать с конфигом из скрипта. Указанный в скрипте Endpoint engage.cloudflareclient.com разрешается в два адреса ipv6 и ipv4. Скрипт в качестве конфига, судя по всему, прописывает ipv6 адрес. Как только скрипт срабатывает, туннель wireguard в web-интерфейсе сразу падает. Что я неправильно делаю/понимаю?
-
Нашел, спасибо. wireguard-tools Да, в курсе, буду апгрейдиться до 3.8 в delta, как выйдет.
-
у меня 3.7.4. Насколько понимаю, в этом случае надо просто добавить для ipv6 адрес на интерфейс Wireguard и AllowedIPs в параметры туннеля. Адрес добавляется без проблем, а AllowedIPs нет: (config)> interface Wireguard2 wireguard peer <Public Key peer-а> allow-ips ::/0 Command::Base error[7405602]: address: argument parse error. Похоже, в CLI также не предусмотрена установка параметров Wireguard для ipv6, как и в веб интерфейсе. Также я не могу воспользоваться и вашим способом, т.к. у меня нет команды wg. Из какого пакета Entware она? Я верно понял вот это ваше замечание "нужен ещё аналог ipv6 nat Wireguard2, например для warp. А иначе с br0 идут реальные ipv6 адреса", что пакеты из туннеля приходят с ipv6 warp-а, а не пира в этом туннеле Wireguard...? Почему так, ведь у вас же прописан маскарадинг ip6t POSTROUTING -t nat -o nwg2 -j MASQUERADE ?
-
Если я, наконец, правильно Вас понял, то update-dhcp в действительности поддерживается, просто его забыли описать. Ок, спасибо еще раз. Попробую все это доделать на днях. И все же последнее не правильнее ли это делать через файл hosts? можете, что сказать по полному отказу от ndhcps в пользу dnsmasq, что я мог неверно сделать и мне следует проверить?
-
Все же я что-то не понимаю. Вы же сами выше писали, что действие update-dhcp не поддерживается в neighbour.d, т.е. скрипт update-dhcp.sh не будет никогда запускаться.